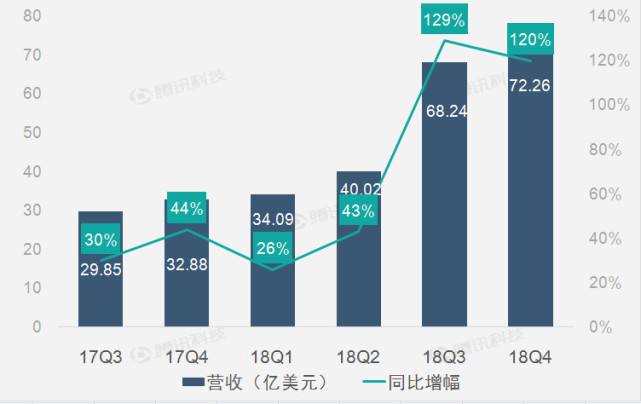
旧金山:
旧金山:
周三,社交媒体Reddit对人工智能公司Anthropic提起诉讼,指控该初创公司在未经许可或赔偿的情况下非法收集数百万用户评论来训练其Claude聊天机器人。
这场在加州一家州法院提起的诉讼,代表了内容提供商和人工智能公司之间围绕如何使用数据来训练日益复杂的语言模型而展开的日益激烈的斗争的最新战线。这些语言模型为生成式人工智能革命提供了动力。
Anthropic估值615亿美元,得到了亚马逊的大力支持,由ChatGPT的创造者OpenAI的前高管于2021年创立。
该公司以其Claude聊天机器人和人工智能模型而闻名,该公司将自己定位为专注于人工智能安全和负责任的开发。
“这起案件是关于Anthropic的两张面孔:一面是试图通过宣称正义、尊重边界和法律来迎合消费者意识的公众面孔,另一面是无视任何妨碍其进一步中饱私袋的规则的私人面孔,”诉讼称。
根据起诉书,至少从2021年12月开始,Anthropic就一直在Reddit内容上训练其模型,首席执行官达里奥·阿莫代伊(Dario Amodei)与人合著了研究论文,专门为数据训练确定了高质量的内容。
该诉讼称,尽管Anthropic公开声称已阻止其机器人访问Reddit,但该公司的自动化系统在随后的几个月里继续收集Reddit服务器的数据超过10万次。
Reddit正在寻求经济赔偿和法院禁令,以迫使Anthropic遵守其用户协议条款。该公司要求陪审团审判。
在给法新社的一封电子邮件中,Anthropic表示:“我们不同意Reddit的说法,并将大力捍卫自己。”
人工智能公司通常通过声称合理使用来为自己的做法辩护,认为在大型数据集上训练人工智能从根本上改变了原始内容,是创新的必要条件。法新社
周三,社交媒体Reddit对人工智能公司Anthropic提起诉讼,指控该初创公司在未经许可或赔偿的情况下非法收集数百万用户评论来训练其Claude聊天机器人。
这场在加州一家州法院提起的诉讼,代表了内容提供商和人工智能公司之间围绕如何使用数据来训练日益复杂的语言模型而展开的日益激烈的斗争的最新战线。这些语言模型为生成式人工智能革命提供了动力。
Anthropic估值615亿美元,得到了亚马逊的大力支持,由ChatGPT的创造者OpenAI的前高管于2021年创立。
该公司以其Claude聊天机器人和人工智能模型而闻名,该公司将自己定位为专注于人工智能安全和负责任的开发。
“这起案件是关于Anthropic的两张面孔:一面是试图通过宣称正义、尊重边界和法律来迎合消费者意识的公众面孔,另一面是无视任何妨碍其进一步中饱私袋的规则的私人面孔,”诉讼称。
根据起诉书,至少从2021年12月开始,Anthropic就一直在Reddit内容上训练其模型,首席执行官达里奥·阿莫代伊(Dario Amodei)与人合著了研究论文,专门为数据训练确定了高质量的内容。
该诉讼称,尽管Anthropic公开声称已阻止其机器人访问Reddit,但该公司的自动化系统在随后的几个月里继续收集Reddit服务器的数据超过10万次。
Reddit正在寻求经济赔偿和法院禁令,以迫使Anthropic遵守其用户协议条款。该公司要求陪审团审判。
Anthropic在给法新社的一封邮件中说:“我们不同意Reddit的说法,并将大力捍卫自己。”
人工智能公司通常通过声称合理使用来为自己的做法辩护,认为在大型数据集上训练人工智能从根本上改变了原始内容,是创新的必要条件。法新社
转载请注明出处: iNCAP英凯教育
本文的链接地址: http://boss.incaponline.cn/post-8949.html
本文最后发布于2025年06月10日02:30,已经过了0天没有更新,若内容或图片失效,请留言反馈
-

联合国人道主义机构将裁员20%,原因是资金“大幅削减”
联合国(美联社)——联合国人道主义机构表示,由于资金“大幅削减”,该机构在60多个国家的2600名工作人员将减少20%,这使得该机构出现了近6000万美元的缺口。联合国人道主义事务负责人汤姆·弗莱彻在美联社星期五获得的一封信中说,在最近的资金削减之前,“人道主义界已经资金不足,过度紧张,实际上受到攻击”。在给该机构工作人员的信中,他没有说哪个国家应该为导致联...
2025/04/21
-
油人队以4-2战胜鲨鱼队获得季后赛席位
周五,埃德蒙顿油人队以4比2战胜最后一名圣何塞鲨鱼队,正式锁定了季后赛席位。“特殊的团队是今晚比赛的重要组成部分,”油人队主教练克里斯·克诺布劳赫在获胜后说。“有了我们的杀戮,有了大多数的权力游戏,我们就能兑现这些。”“这场权力游戏看起来与以往大不相同。我们在进攻区花了很多时间,显然我们能够把一些球打进网里。但我认为很多事情都是从恩里克赢得对抗赛开始的,所以...
2025/04/21
-
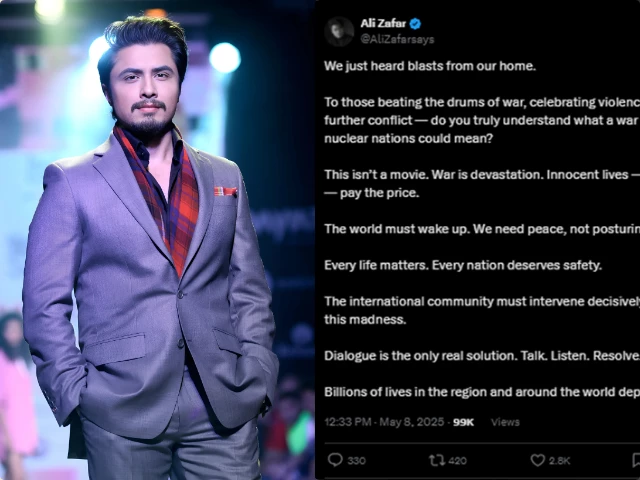
扎法尔敦促通过对话解决巴印危机,他说,战争就是破坏
巴基斯坦歌手兼演员阿里·扎法尔呼吁印度和巴基斯坦之间的边界紧张局势加剧,进行紧急对话和国际干预。在周四发布的一系列强有力的推文中,扎法尔敦促两国保持克制,警告两个拥有核武器的国家之间发生战争的灾难性后果。“我们刚刚从家里听到爆炸声,”扎法尔写道,他指的是据报道巴基斯坦军队进行的空中拦截,目的是阻止从边境进入的无人机。“对于那些敲着战鼓的人……你真的明白两个核...
2025/05/13
-
马可·卢比奥在与阿西姆·穆尼尔的通话中敦促缓和局势
听文章据美国国务院发言人透露,周六,美国国务卿马可·卢比奥与印度陆军参谋长阿西姆·穆尼尔将军通电话,呼吁双方保持克制,敦促巴基斯坦和印度双方立即缓和紧张局势。“...
2025/05/12
-
伊比在给卡尼的信中呼吁与联邦政府合作进入新时代
不列颠哥伦比亚省总理致信该国新当选的总理,列出了该省的优先事项。在一封日期为周四的信中,大卫·埃比祝贺马克·卡尼赢得选举,并敦促他“致力于联邦-省-地区合作的新时代”。在此之前,卡尼在竞选活动中把自己定位为在美国总统唐纳德·特朗普的关税和吞并威胁的阴影下支持加拿大经济和主权的最佳准备。一13马克·卡尼公元...
2025/05/02
-
唐纳德·特朗普“想当教皇”
听文章本月初教皇方济各去世后,美国总统唐纳德·特朗普开玩笑地表示,教皇方济各将是他自己领导天主教会的首选。“我想当教皇,”特朗普在被记者问及教皇继承问题时笑着说...
2025/05/06
-
在香港,人们聚集在一起庆祝百年包头节
香港(美联社)——人群涌向香港偏远的周洲岛,庆祝每年举行的包子节,这是一个有百年历史的传统,旨在驱除邪恶,祈求和平和祝福。庆祝活动以一群穿着“漂色”(PiuSik)服装的孩子游行开始,“漂色”翻译过来就是“漂浮的颜色”。孩子们打扮成传说中的神灵或历史人物,被抱在聚集的人群上方的看台上,蜿蜒穿过岛上狭窄的小巷。节日的重头戏是午夜时分的“抢包”比赛,攀爬者竞相...
2025/05/10
-
健康保险:解决退休计划中的长期护理费用
健康保险在管理长期护理费用方面起着至关重要的作用,长期护理费用是退休人员非常关心的问题。有效地规划财务是必不可少的,因为这些费用可能超过10万美元。这篇文章探讨了为退休人员量身定制的财务咨询和个人理财技巧的重要策略。健康保险:解决退休计划中的长期护理费用健康保险:为长期护理费用做准备健康保险对面临大量长期护理费用的退休人员至关重要。潜在的开支远远超过$100...
2025/05/26
-
在GHQ案中,ATC向PTI领导人发出逮捕令
拉瓦尔品第:拉瓦尔品第反恐法庭(ATC)法官SyedAmjadAliShah周五对34名潜逃被告发出逮捕令,其中包括与GHQ袭击案有关的PTI领导人ShehryarAfridi、KanwalShauzab、MusarratJamshedCheema和UmarTanveerButt。法院命令警方逮捕被告,并在5月29日之前将他们送上法庭。周五...
2025/05/24
-
百老汇的步行区
距离百老汇大桥关闭只有两周了,河两岸的企业和组织都在争先恐后地确保他们做好了准备。为了在大桥修复期间将人们吸引到百老汇,强镇YXE提出了一个步行区。获取每日全国新闻获取当天的头条新闻,政治,经济和时事头条,每天发送到您的收件箱一次。通过提供您的电子邮件地址,您已阅读并同意环球新闻的条款和条件以及隐私政策。该区域将在7月和8月活跃,横跨百老汇的两个街区,允许商...
2025/05/05